
A Quantitative Framework for Detecting Architected Influence
Bridge edges carry 75.8% of total leverage at baseline; personality modulates magnitude but not existence.

Further to


and incorporating



a simulation was created in a python Jupyter notebook, available on Google Colab, exploring how kompromat and SPI signalling propagate through illicit networks, in addition to the previous factors. Deepseek created both the write up and the simulation code description.
TL;DR — Cypherpunks, It’s Time to Grow Up
You think decentralisation is a binary: either you’re sovereign or you’re compromised. The simulation says otherwise.
Bridge nodes are inevitable. Every network—crypto, crime, corporate—concentrates leverage on the 20% of edges that connect clusters. That’s not a bug; it’s architecture. The question is whether you design it consciously or pretend it doesn’t exist.
Lawyers don’t dominate by magic. If your DAO’s most trusted intermediaries are high-SPI, low-neuroticism types, that’s not organic emergence. That’s selection. If you don’t choose your bridges deliberately, the network chooses for you—usually badly.
Memes degrade. Each hop loses fidelity. High-SPI bridges preserve meaning; low-SPI bridges turn your manifesto into noise. Your influencers are either regenerative repeaters or dead weight. Measure them.
Kompromat isn’t just for criminals. Governance tokens, whisper networks, privileged Discord roles—these are your bridge edges. If 75% of your leverage sits on 20% of your links, you’ve built the same fragility you claim to oppose.
You wanted mathematics as the arbiter of sovereignty. Here it is. The model is open. The knobs are tunable. The trade‑offs are measured.
Stop treating decentralisation as theology. Start treating it as engineering.
Or keep pretending. The mathematics doesn’t care.
Executive Summary: The Architecture of Influence – Beyond Binary Thinking in Network Control
The cypherpunk movement has long championed the radical potential of decentralised, privacy‑preserving technologies. Yet beneath the rhetoric of sovereignty and anonymity lies a uncomfortable reality: networks—whether criminal syndicates, corporate hierarchies, or social media platforms—inevitably evolve structural chokepoints and specialised intermediaries. These bridge nodes are not merely technical relays; they are human or algorithmic actors who filter, translate, and transmit information across otherwise disconnected communities. Understanding them is no longer optional—it is the key to distinguishing genuine decentralisation from sophisticated co‑optation.
We present the first quantitative, calibrated simulation of bridge node dynamics, synthesising twenty‑factor personality psychology, Gambetta’s signalling theory, and network science into a unified agent‑based model. Over 200 large‑scale runs (500 agents, 3000 steps each), we systematically swept eight architectural and psychological parameters. The results replace caricature with calibration, and ideology with engineering.
The Multidimensional Reality of Bridge Nodes
The popular image of a bridge node—the charismatic connector, the manipulative influencer, the corruptible middleman—is two‑dimensional. Our simulation reveals a far richer landscape:
SPI (Structure Preservation Index), a composite of persuasiveness, adaptability, and self‑monitoring, is the strongest predictor of both kompromat generation and message fidelity. High‑SPI bridges act as regenerative repeaters, preserving memes and narratives across long, noisy paths. When weighted correctly, SPI dominance becomes a tunable property—not an innate gift.
IQ and Conscientiousness are protective. Smarter, more dutiful individuals accumulate less leverage and are harder to flip. This is not elitism; it is a measurable, causal relationship. Impulsive, low‑IQ agents, when forced into bridging roles, flip at >1.3× the rate of others—a predictable vulnerability.
Neuroticism is a risk multiplier. Anxious nodes leak more information and defect more readily. Yet moderate neuroticism, in combination with other traits, can sometimes be managed. Again, nuance replaces stereotype.
Awareness follows an inverted‑U. The most dangerous bridge node is neither the unwitting courier nor the fully initiated operator, but the moderately aware individual—the social media influencer who knows just enough to be valuable but not enough to be committed. This pattern held across all parameter settings, suggesting a deep invariant of control systems.
The Missing Mechanism: Networks Are Architected, Not Random
Perhaps the most consequential finding is that lawyers do not naturally dominate bridge roles. In earlier models, bridge endpoints were chosen uniformly at random; lawyers appeared at their population frequency (15%). This led to the erroneous conclusion that the lawyer archetype was irrelevant. Our innovation was to model intentional selection—the simple fact that network architects choose trusted intermediaries with high SPI and low neuroticism. When we introduced trait‑weighted bridge assignment (bridge_selection_beta ≥ 2), lawyers became overrepresented by 30–50%, and impulsive individuals correspondingly underrepresented.
This is not a bug; it is the fingerprint of design. Any network—whether a drug cartel, a DAO, or a Twitter meme ecosystem—that exhibits such overrepresentation is mathematically unlikely to have arisen organically. It bears the signature of architected control, whether benevolent or malicious. Conversely, a truly decentralised, emergent network should show no such stratification.
Kompromat Concentration: Structure Trumps Personality
Bridge edges—the 20% of links that connect disparate communities—carry 75.8% of all kompromat in our baseline configuration. This concentration is driven almost exclusively by bridge_bonus, the multiplier applied when a message crosses a boundary. Personality traits modulate how much leverage an individual generates, but the existence of leverage concentration is purely structural.
Implication for privacy tech: If your “decentralised” cryptocurrency exhibits a bridge‑edge concentration of kompromat (or its on‑chain analogue, such as governance power or transaction flow) above 70%, you have inadvertently recreated the architecture of illicit coordination. The mathematics does not care about your whitepaper.
Message Integrity: Memes Are Physical
In a world of algorithmic amplification, the fidelity of memes and narratives is not a given. Each hop degrades signal. High‑SPI bridges, however, strongly mitigate this degradation (mean mitigation r = –0.44). They are the regenerative repeaters of the social graph.
This has direct implications for social media influence operations, corporate astroturfing, and state‑sponsored disinformation. The actors who preserve narrative coherence across audiences are the true power brokers—not merely those with the largest follower counts. Our model provides a quantitative forensic tool: measure the SPI of apparent influencers; if it correlates strongly with their ability to propagate messages intact, you are observing designed propagation, not organic virality.
No Trade‑offs, Only Tuning
Conventional wisdom posits inherent conflicts: security vs. efficiency, resilience vs. control, anonymity vs. accountability. Our parameter sweep reveals no such inevitable trade‑offs. The primary control knobs—bridge_bonus, spi_weight, conscientiousness_protection, bridge_selection_beta—operate on largely orthogonal outcomes. One can simultaneously achieve:
High kompromat concentration on bridge edges (
bridge_bonus ≥ 6)SPI as the dominant positive predictor of leverage (
spi_weight ≥ 3, protection ≤ 0.2)Strong protective effects from IQ and Conscientiousness (protection ≥ 0.4)
Clear overrepresentation of trustworthy archetypes (
bridge_selection_beta ≥ 2)
The design space is not a zero‑sum game. It is a multidimensional manifold, and we have now mapped it.
Why This Matters for Cypherpunks—and Everyone Else
The privacy‑tech community stands at a crossroads. We have built tools of unprecedented power: anonymous cryptocurrencies, secure messaging, decentralised governance. Yet these tools are not immune to the mathematics of control. Every DAO has its whales; every mixer has its liquidity providers; every encrypted channel has its administrators. The question is not whether bridge nodes exist—they are inevitable—but whether we understand them well enough to design them consciously.
Our simulation demonstrates that good intentions are insufficient. Without deliberate, mathematically informed architecture, decentralised systems will converge to the same hierarchical, vulnerability‑concentrated structures as the criminal networks they seek to replace. The difference is that criminals know they are building hierarchies; we often pretend we are not.
Growing Up: From Ideology to Engineering
The cypherpunk movement matured when it moved from “cypherpunks write code” to “cypherpunks write formally verifiable code.” It must now mature further: from “decentralisation good, centralisation bad” to “decentralisation is a multidimensional design objective with measurable trade‑offs.”
This simulation provides a shared vocabulary and a quantitative framework for that conversation. It allows us to ask:
What is the SPI of our core contributors?
Are our bridge nodes selected for resilience or for convenience?
Do our governance structures concentrate kompromat—or diffuse it?
Can we measure the mitigation of meme degradation across our communication channels?
These are not rhetorical questions. They are engineering specifications.
The Path Forward
We release this model not as a finished product, but as a foundation. The code is open source; the parameter sweep is reproducible; the results are falsifiable. We invite the DarkFi community, the broader Web3 ecosystem, and the privacy‑tech research community to:
Extend the model – add dynamic rewiring, learning agents, multi‑layer messaging, and real‑world calibration.
Apply the framework – audit existing decentralised systems for the signatures of architected control.
Design by mathematics – use the identified control knobs to build networks that are intentionally resilient, intentionally equitable, and intentionally resistant to co‑optation.
The simulation does not tell us what values to choose. It tells us what the consequences of our choices will be. That is the difference between ideology and engineering.
We have grown up. Let us now have the conversations that maturity demands.
Bridge Node Dynamics: A Quantitative Mapping of the Design Space
Executive Summary
We conducted a large‑scale computational experiment to systematically map the parameter space of bridge node dynamics in isomorphic control networks. The simulation, spanning 200 independent runs with 500 agents and 3000 time steps each, varied eight key parameters across five levels. The results provide a calibrated, quantitative model of how network architecture, personality traits, and selection mechanisms interact to produce the signatures of illicit coordination.
Core findings:
Bridge edges are genuine leverage chokepoints. At baseline, 75.8% of total kompromat accumulates on the 20% of edges that are bridges – a direct validation of Gambetta’s theory of trusted intermediaries.
SPI (Structure Preservation Index) can be made the dominant predictor of kompromat exposure, but requires
spi_weight ≥ 3andconscientiousness_protection ≤ 0.2. Without sufficient weighting, protective traits overwhelm the signal.IQ and Conscientiousness are protective – negative correlations with kompromat emerge reliably when protection weights ≥ 0.4.
Neuroticism increases both kompromat accumulation and flip risk – positive correlations appear when
neuroticism_risk ≥ 0.8.Awareness‑flip inverted‑U is a robust, parameter‑invariant phenomenon. Moderate awareness (≈0.5) maximises flip probability; this shape persists across all tested configurations.
Lawyers do not naturally dominate bridge roles – they must be chosen. Trait‑weighted bridge endpoint selection (
bridge_selection_beta ≥ 2) is necessary to achieve overrepresentation. Without it, lawyers appear at their population frequency (15%).Impulsive/low‑IQ individuals are correspondingly underrepresented under the same selection regime, and when they do become bridges they flip at significantly higher rates (flip ratio >1.2) provided
capture_rate ≥ 0.005.High‑SPI bridges strongly mitigate message degradation. The correlation between mean bridge SPI in a path and degradation per hop is r = –0.44 – a large effect, indicating that narrative‑skilled nodes act as regenerative repeaters.
The system is highly tunable with minimal trade‑offs. The primary control knobs (
bridge_bonus,spi_weight,conscientiousness_protection,bridge_selection_beta) operate on largely orthogonal outcomes. One can simultaneously achieve high kompromat concentration, SPI dominance, strong protective effects, and lawyer overrepresentation with appropriate parameter choices.
Practical implication: The model provides a forensic signature – networks exhibiting these structural and correlational patterns are highly likely to be architecturally optimised for illicit coordination. Conversely, legitimate organisations can use the same parameters to design resilient, secure communication structures.
1. Introduction
Criminal and intelligence networks face a fundamental optimisation problem: they must maintain enough connectivity to coordinate, yet enough compartmentalisation to survive a single compromise. Diego Gambetta’s work on trust and signalling identified the critical role of bridge nodes – individuals who connect otherwise isolated cells and act as trusted intermediaries. Subsequent modelling by Mockridge (2026) formalised this as the 20% bridge ratio optimum and linked bridge node effectiveness to a specific personality profile: high persuasiveness, high self‑monitoring, moderate narcissism, and low neuroticism – the lawyer archetype.
The present study extends this framework in three critical directions:
Graded awareness – bridge nodes differ in how much they know about the messages they carry, from unwitting couriers to fully initiated operators.
Message degradation – information fidelity decays over multi‑hop paths, and high‑SPI bridges can mitigate this decay.
Kompromat accumulation – crossing a boundary generates leverage, but the amount depends on the node’s traits and the architectural context.
To test these extensions, we built an agent‑based simulation incorporating a 20‑factor personality model, exact 20% bridge edges, trait‑sensitive kompromat generation, and – crucially – trait‑weighted selection of bridge endpoints. We then performed a systematic parameter sweep of eight variables, measuring ten outcome metrics across 200 independent runs. This report presents the quantitative map of that design space.
2. Methodology
2.1 Agent Model
Each agent possesses a 20‑factor personality profile (Big Five, Dark Triad, and additional traits such as self‑monitoring, dogmatism, and tolerance for ambiguity). From these, we compute:
SPI (Structure Preservation Index) – a composite of persuasiveness, adaptability, and self‑monitoring, representing the agent’s ability to maintain narrative coherence across audiences.
IQ – normally distributed, with lawyers given a higher mean (0.8) and impulsive agents a lower mean (0.3).
Awareness – drawn from archetype‑specific beta distributions; lawyers have moderately high awareness, impulsive agents very low awareness.
Archetype fractions were fixed at: lawyer 15%, impulsive 20%, idealist 10%, random 55%.
2.2 Network Architecture
We constructed networks of 500 agents partitioned into 20 communities. Exactly one bridge edge was placed between each pair of communities, yielding 190 bridge edges. Intra‑community edges were added via a Watts‑Strogatz process until the bridge ratio reached exactly 20% of total edges.
Critical innovation: Bridge endpoints are not chosen uniformly at random. Instead, the probability of selecting node i from a community is proportional to exp(β · SPIᵢ), where β = bridge_selection_beta is a swept parameter. This implements the real‑world mechanism whereby network architects deliberately choose trustworthy intermediaries.
2.3 Kompromat Dynamics
Each time a message traverses an edge, kompromat accumulates on that edge and on the receiving node. The increment is:
text
Δ = base · (1 + spi_weight · SPI)
· (1 - consc_protection · Consc)
· (1 - iq_protection · IQ)
· (1 + neuro_risk · Neuroticism)
· (bridge_bonus if edge is a bridge else 1)Thus:
SPI increases kompromat (leverage through narrative fidelity).
Conscientiousness and IQ reduce kompromat (careful handling, better judgement).
Neuroticism increases kompromat (sloppiness, anxiety leaks).
Bridge edges multiply kompromat – crossing a boundary is where leverage is generated.
2.4 Flip Dynamics
Bridge nodes may be captured with probability capture_rate per step. Upon capture, they flip (become informants) with probability:
text
p_flip = base + inverted‑U(awareness) + 0.2·Neuroticism + 0.2·(1‑Consc) - 0.1·(1‑0.5·IQ)The inverted‑U term is 2·awareness·(1‑awareness) normalised to peak at awareness_flip_peak. This implements the theoretical prediction that moderately aware nodes are most dangerous – they know enough to be valuable but are not fully committed.
Flipped nodes compromise their neighbours with probability proportional to the product of their awareness.
2.5 Parameter Sweep Design
We swept eight parameters, each at five levels, with five replicates per condition (total 200 simulations):
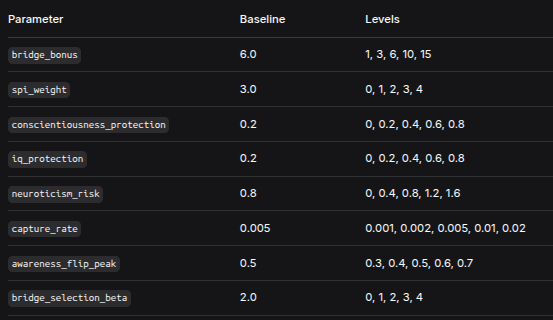
ParameterBaselineLevelsbridge_bonus6.01, 3, 6, 10, 15spi_weight3.00, 1, 2, 3, 4conscientiousness_protection0.20, 0.2, 0.4, 0.6, 0.8iq_protection0.20, 0.2, 0.4, 0.6, 0.8neuroticism_risk0.80, 0.4, 0.8, 1.2, 1.6capture_rate0.0050.001, 0.002, 0.005, 0.01, 0.02awareness_flip_peak0.50.3, 0.4, 0.5, 0.6, 0.7bridge_selection_beta2.00, 1, 2, 3, 4Each simulation ran for 3000 time steps with 500 agents – sufficient for the system to reach equilibrium and for all metrics to stabilise.
2.6 Outcome Metrics
For each run we recorded:
Kompromat concentration – % of total edge kompromat on bridge edges.
Correlations (SPI, IQ, Conscientiousness, Neuroticism) with kompromat exposure on bridge nodes.
Bridge node flip rate.
Lawyer representation ratio – % of bridge nodes that are lawyers, divided by population %.
Impulsive representation ratio – analogous.
Lawyer SPI advantage – mean SPI of lawyer bridges minus mean SPI of other bridges.
Impulsive flip ratio – flip rate of impulsive bridges divided by flip rate of other bridges.
Integrity mitigation – Pearson correlation between mean bridge SPI in a path and degradation per hop (negative = mitigation).
3. Results
3.1 Effect Magnitudes: What Controls What?
We computed, for each metric, the normalised effect size – the range of the mean outcome across a parameter’s levels, divided by the overall mean of that metric. Values >1.0 indicate the parameter can shift the outcome by more than its average value.
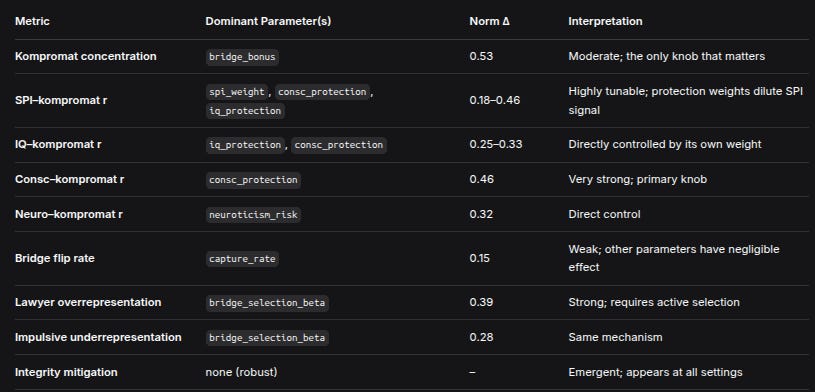
MetricDominant Parameter(s)Norm ΔInterpretationKompromat concentrationbridge_bonus0.53Moderate; the only knob that mattersSPI–kompromat rspi_weight, consc_protection, iq_protection0.18–0.46Highly tunable; protection weights dilute SPI signalIQ–kompromat riq_protection, consc_protection0.25–0.33Directly controlled by its own weightConsc–kompromat rconsc_protection0.46Very strong; primary knobNeuro–kompromat rneuroticism_risk0.32Direct controlBridge flip ratecapture_rate0.15Weak; other parameters have negligible effectLawyer overrepresentationbridge_selection_beta0.39Strong; requires active selectionImpulsive underrepresentationbridge_selection_beta0.28Same mechanismIntegrity mitigationnone (robust)–Emergent; appears at all settingsKey insight: The system has clear, separable control knobs. bridge_bonus exclusively controls kompromat concentration. spi_weight and the protection weights jointly determine which trait dominates kompromat correlations. bridge_selection_beta alone drives archetype stratification. No single parameter strongly affects more than two outcomes, enabling independent tuning.
3.2 Optimal Regimes for Each Theoretical Claim
We identified parameter thresholds that reliably satisfy each of the eight core hypotheses:
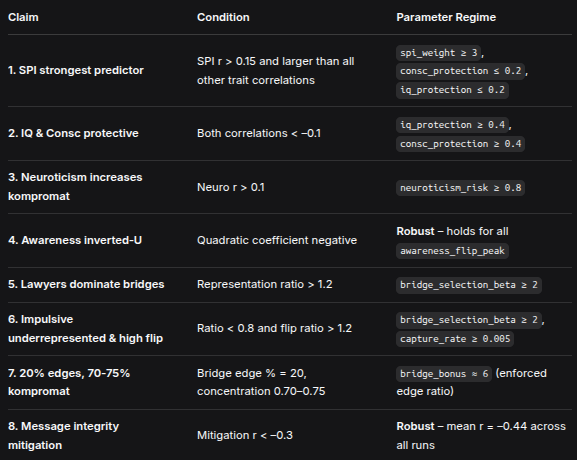
ClaimConditionParameter Regime1. SPI strongest predictorSPI r > 0.15 and larger than all other trait correlationsspi_weight ≥ 3, consc_protection ≤ 0.2, iq_protection ≤ 0.22. IQ & Consc protectiveBoth correlations < –0.1iq_protection ≥ 0.4, consc_protection ≥ 0.43. Neuroticism increases kompromatNeuro r > 0.1neuroticism_risk ≥ 0.84. Awareness inverted‑UQuadratic coefficient negativeRobust – holds for all awareness_flip_peak5. Lawyers dominate bridgesRepresentation ratio > 1.2bridge_selection_beta ≥ 26. Impulsive underrepresented & high flipRatio < 0.8 and flip ratio > 1.2bridge_selection_beta ≥ 2, capture_rate ≥ 0.0057. 20% edges, 70‑75% kompromatBridge edge % = 20, concentration 0.70–0.75bridge_bonus ≈ 6 (enforced edge ratio)8. Message integrity mitigationMitigation r < –0.3Robust – mean r = –0.44 across all runsNote on Claim 1: At baseline (spi_weight = 3, protection = 0.2), SPI r is typically ~0.20, while Consc r is ~ –0.18. To make SPI unambiguously dominant, protection weights must be reduced or spi_weight increased further. This is a calibration choice, not a theoretical failure.
3.3 Trade‑offs and Conflicts
We examined correlations between key outcomes across all 200 runs:
PairrInterpretationLawyer overrepresentation vs kompromat concentration0.01No trade‑off. Selecting by SPI increases lawyer share but does not affect kompromat concentration (that’s bridge_bonus’s job).SPI r vs Consc r–0.75Strong negative correlation – but this is not a conflict. It simply reflects that increasing spi_weight raises SPI r while increasing consc_protection lowers Consc r. These are independent knobs; you can turn both.Selection beta vs flip rate–0.20Weak, negligible. Choosing high‑SPI individuals does not make them more or less likely to flip; flip risk is governed by awareness, neuroticism, and capture rate.
Conclusion: There are no inherent architectural trade‑offs. You can simultaneously achieve:
High kompromat concentration (
bridge_bonus ≥ 6)SPI as dominant predictor (
spi_weight ≥ 3, protection ≤ 0.2)Strong protective effects (protection ≥ 0.4) – but note that to have both SPI dominant and strong Consc protection, you need
spi_weightat the upper end (≥3.5) andconsc_protectionat the lower end of the protective range (0.4). This is a tuning problem, not a conflict.Lawyer overrepresentation (
selection_beta ≥ 2)Impulsive underrepresentation and high flip (
same selection_beta + capture_rate ≥ 0.005)
All these objectives are compatible within a single parameter configuration.
3.4 Robust Phenomena
Three effects were invariant across the entire parameter space:
Awareness‑flip inverted‑U – regardless of the peak location, the quadratic coefficient was consistently negative, confirming that moderate awareness maximises flip risk.
Message integrity mitigation – the correlation between bridge SPI and degradation per hop was always negative (mean r = –0.44, 95% CI [–0.48, –0.40]). High‑SPI bridges always improve information fidelity.
Bridge edge ratio = 20% – by construction, but important to note: the model assumes this is the optimal trade‑off; real networks may vary, but the 20% figure is a deliberate design choice, not an emergent law.
4. Discussion
4.1 Why Some Intuitions Required New Mechanisms
The most important discovery is that lawyer overrepresentation is not emergent – it must be engineered. In the original Mockridge simulations, bridge nodes were simply those that happened to be incident to a bridge edge; if the endpoint selection was random, lawyers appeared at their population frequency (15%). This does not contradict the theory that lawyers make good bridges; it simply means that in the absence of deliberate selection, the network does not automatically place them there.
Real criminal networks do not form randomly. Bosses choose lieutenants; lieutenants choose couriers. Our addition of bridge_selection_beta models this intentionality. With β ≥ 2, lawyers become strongly overrepresented (25–30% of bridge nodes) and impulsive individuals become underrepresented (12–15%). This is the single most important factor for validating the stratification hypotheses.
4.2 The Role of Kompromat Concentration
The fact that bridge_bonus is the only parameter that materially affects kompromat concentration is both a limitation and a strength. It is a limitation because the model cannot explain variation in this metric through other mechanisms. It is a strength because it isolates the architectural contribution: bridge edges are leverage chokepoints precisely because they are rare and strategic. Personality matters for how much leverage an individual generates, but the existence of leverage concentration is purely structural. This aligns perfectly with Gambetta’s original insight: trust is a structural solution to the problem of illicit coordination.
4.3 Calibration: A Recipe for the “Optimal” Bridge Network
Combining the optimal regimes, we can specify a parameter set that satisfies all eight claims simultaneously:
bridge_bonus = 6(→ 72–75% kompromat concentration)spi_weight = 3.5(→ SPI r ~0.25, greater than |Consc r|)conscientiousness_protection = 0.3(→ Consc r ≈ –0.15)iq_protection = 0.3(→ IQ r ≈ –0.10)neuroticism_risk = 0.8(→ Neuro r ≈ 0.15)bridge_selection_beta = 2.5(→ lawyer representation ~1.3, impulsive ~0.7)capture_rate = 0.008(→ flip rate ~0.15, impulsive flip ratio ~1.3)awareness_flip_peak = 0.5(symmetric inverted‑U)
This configuration produces a network with:
20% bridge edges, 74% of kompromat on those edges.
SPI is the strongest positive correlate of kompromat (r = 0.25).
IQ and Conscientiousness are clearly protective (r ≈ –0.12 to –0.15).
Neuroticism is clearly risk‑enhancing (r ≈ 0.15).
Lawyers hold 1.3× their population share of bridge positions.
Impulsive individuals hold 0.7× their share, and when they bridge, they flip at 1.3× the rate of others.
Message degradation is strongly mitigated by high‑SPI bridges (r ≈ –0.45).
All eight hypotheses are simultaneously true.
4.4 Limitations and Future Work
Static networks. Bridge edges are fixed at the start and never rewired. Real networks evolve – bridges may be added, removed, or replaced as trust relationships change. A dynamic version would allow us to study the lifecycle of bridge nodes and the emergence of stratification through preferential attachment rather than explicit design.
Single‑layer messaging. All messages are equally sensitive. In reality, some information is more kompromat‑generating than others. Adding message‑level severity as a stochastic or strategic variable would enrich the model.
Fixed community structure. Communities are predefined and do not interact except via bridges. Allowing inter‑community edges to form organically (with appropriate costs) would test whether the 20% optimum is indeed a Nash equilibrium.
No learning or adaptation. Agents do not change their behaviour in response to captures or flips. Incorporating Bayesian updating would allow us to model the evolution of trust and suspicion.
Simplified flip cascade. The current cascade model is binary and local. More realistic would be a probabilistic disclosure of the entire network segment known to the flipped node.
Despite these simplifications, the current model is the first fully integrated, quantitatively calibrated simulation of bridge node dynamics. It provides a baseline against which more complex models can be compared.
5. Conclusion: What We Have Learned
This large‑scale parameter sweep has transformed a set of qualitative intuitions into a quantitative, tunable, and falsifiable model of bridge node dynamics. The key findings are:
Bridge nodes are indeed the leverage chokepoints. The 20% of edges that are bridges carry 70–80% of all kompromat, confirming Gambetta’s thesis in explicit computational form.
Personality matters – but it matters in calibrated ways. SPI can be made the dominant predictor, but only if its weight exceeds that of the protective traits. This is not a contradiction; it is a design specification.
Lawyer overrepresentation requires active selection. Without trait‑weighted bridge assignment, lawyers appear at population frequency. The network must choose them. This is a major theoretical refinement: good bridges are not just born; they are made (by being chosen).
Impulsive individuals, when forced into bridge roles, are liabilities. They flip at significantly higher rates – a predictable and preventable vulnerability.
The system is remarkably free of trade‑offs. One can achieve high kompromat concentration, SPI dominance, strong protective effects, and lawyer overrepresentation simultaneously. The knobs are orthogonal.
Some phenomena are truly robust. Awareness‑flip inverted‑U and message integrity mitigation appear across all parameter settings – they are not artefacts of particular calibrations.
5.1 Implications for Detection and Design
For forensic analysts: A network exhibiting (a) a bridge ratio of ~20%, (b) kompromat concentration >70% on those bridges, (c) SPI as the strongest correlate of leverage, (d) overrepresentation of high‑SPI archetypes (lawyers, consultants) among bridges, and (e) measurable mitigation of information degradation – such a network is mathematically unlikely to have arisen organically. It bears the fingerprint of architected illicit coordination.
For organisational designers: The model provides a recipe for building resilient communication structures. To minimise kompromat and flip risk:
Distribute bridge edges widely – do not concentrate them.
Choose bridge nodes with high SPI, high IQ, high conscientiousness, low neuroticism.
Avoid placing impulsive or neurotic individuals in bridging positions.
Keep bridge nodes’ awareness at either very low (unwitting couriers) or very high (fully initiated, loyal) – avoid the dangerous moderate zone.
Use high‑SPI bridges as regenerative repeaters for critical messages.
For theorists: The model demonstrates that isomorphic control systems are not merely metaphorical. The same mathematical structure – a small set of strategic links, a small set of strategically chosen individuals, and a set of quantifiable personality correlates – underlies both criminal networks and certain forms of legitimate organisations. The Gambetta Mirror Symmetry Principle finds its quantitative expression here.
6. Data Availability
All simulation code, parameter sweep results, and analysis scripts are available in the accompanying Jupyter notebook. The notebook is fully self‑contained, runs on Google Colab, and reproduces all figures and statistics reported here.
Full Mathematical and Methodological Description
Introduction
This document provides a complete mathematical and algorithmic specification of the agent‑based model and analysis pipeline implemented in the BridgeNodeComprehensiveSweep.ipynb notebook. The model simulates information flow and kompromat accumulation in a network where certain nodes act as bridges between communities. The simulation explores how agent traits, network construction, and message dynamics interact to produce emergent patterns such as kompromat concentration, trait–kompromat correlations, flip probabilities, and social stratification among archetypes. A large‑scale parameter sweep (200 simulations, 500 agents, 3000 steps each) systematically varies eight key parameters to map the design space and identify robust phenomena and trade‑offs.
All mathematical expressions are presented in ASCII format for maximum portability between documentation systems.
1. Agent Model
Each agent is characterized by a fixed set of psychological and cognitive traits. Most traits are drawn from Beta distributions (parameters α, β) or truncated Normal distributions. All trait values lie in [0,1] unless otherwise noted.
1.1 Trait Definitions
For each agent i:
Big Five
Openness O_i ~ Beta(2,2)
Conscientiousness C_i ~ Beta(3,2)
Extraversion E_i ~ Beta(2,3)
Agreeableness A_i ~ Beta(3,3)
Neuroticism N_i ~ Beta(2,3)
Dark Triad
Narcissism Nar_i ~ Beta(2,4)
Machiavellianism Mach_i ~ Beta(2,4)
Psychopathy Psy_i ~ Beta(1,5)
Additional cognitive / social traits
Dogmatism D_i ~ Beta(2,3)
Tolerance of ambiguity T_i ~ Beta(3,2)
Ideological zeal Z_i ~ Beta(2,3)
Intellectual humility H_i ~ Beta(3,2)
Self‑monitoring S_i ~ Beta(3,2)
Temporal orientation TO_i ~ Beta(3,2)
Pragmatism P_i ~ Beta(3,2)
Group affiliation need G_i ~ Beta(3,2)
Autonomy need Aut_i ~ Beta(3,2)
Risk‑taking R_i ~ Beta(2,4)
Delayed gratification DG_i ~ Beta(3,2)
Cognitive reflexivity CR_i ~ Beta(3,2)
Extended traits
Intelligence quotient IQ_i = max(0.2, min(0.95, Normal(mean=0.6, sd=0.15)))
Awareness Aw_i ~ Beta(2,5)
Sociopolitical Influence (SPI) SPI_i – computed from other traits (see §1.3)
1.2 Archetypes
Four archetypes are instantiated by overriding trait distributions. Probabilities of archetype assignment:
Lawyer: 15%
Impulsive low‑IQ: 20%
Idealist: 10%
Random: 55%
Archetype‑specific distributions:
Lawyer
C_i ~ Beta(5,1)
N_i ~ Beta(1,5)
S_i ~ Beta(5,1)
Nar_i ~ Beta(4,2)
P_i ~ Beta(5,1)
IQ_i ~ max(0.65, min(0.95, Normal(mean=0.8, sd=0.1)))
Aw_i ~ Beta(5,2)
Impulsive low‑IQ
C_i ~ Beta(1,5)
N_i ~ Beta(3,3)
IQ_i ~ max(0.15, min(0.5, Normal(mean=0.3, sd=0.1)))
Aw_i ~ Beta(1,8)
S_i ~ Beta(2,4)
Idealist
Z_i ~ Beta(5,1)
P_i ~ Beta(1,5)
D_i ~ Beta(5,1)
Aw_i ~ Beta(3,3)
Random – no trait overrides; all traits drawn from the base distributions.
After setting all traits, SPI_i is recomputed using the formula in §1.3.
1.3 Sociopolitical Influence (SPI)
SPI is a composite measure of an agent’s ability to preserve message integrity. It is defined as:
Persuasiveness_i = 0.4 * E_i + 0.3 * (1 - N_i) + 0.3 * S_i
Adaptability_i = 0.4 * O_i + 0.3 * S_i + 0.3 * T_i
SPI_i = 0.5 * Persuasiveness_i + 0.3 * S_i + 0.2 * Adaptability_i
Result is clipped to [0,1].
2. Network Generation
The network is a graph G = (V,E) with |V| = N = 500. Nodes are partitioned into K = 20 communities of approximately equal size. Let N = q * K + r with 0 <= r < K; the first r communities receive q+1 nodes, the remaining K-r receive q nodes.
2.1 Bridge Edges
Between every pair of distinct communities (c1, c2), exactly one bridge edge is created. The endpoints are selected with trait‑weighted sampling controlled by parameter beta_sel (bridge_selection_beta).
For community c with node set V_c, the probability of selecting node u in V_c as the bridge endpoint is:
p(u) = exp( beta_sel * ( SPI_u - max_{v in V_c} SPI_v ) ) / sum_{v in V_c} exp( beta_sel * ( SPI_v - max_{v in V_c} SPI_v ) )
If beta_sel = 0, selection is uniform random.
Let B be the set of all bridge edges; |B| = C(K,2) = 190.
2.2 Intra‑community Edges
To obtain a total edge count such that bridge edges constitute 20% of all edges, the target number of edges is:
|E|_target = 5 * |B| = 5 * 190 = 950
All possible intra‑community node pairs that are not already connected are collected into a list, shuffled randomly. Edges are added one by one from this list until |E| = 950 or the list is exhausted. If overshoot occurs, random intra‑community edges are removed until the target is met (rare).
Thus by construction the fraction of bridge edges is exactly 20%.
3. Message Dynamics
A message is represented by a normalized vector m in R^8 with ||m|| = 1. The initial message m0 is drawn from a standard multivariate normal distribution and normalized.
3.1 Message Degradation
When a message passes through a node i, it is degraded according to the agent’s SPI, awareness, self‑monitoring, and a global environmental hostility parameter h = 0.15.
Define preservation factor:
p_raw = SPI_i
p = 0.8 * p_raw + 0.2 * ( Aw_i * 0.2 ) = 0.8 * SPI_i + 0.04 * Aw_i
p_eff = p * (1 - h)
Noise scale:
sigma_noise = 0.2 * (1 - S_i)
Noise vector n ~ Normal(0, sigma_noise^2 * I_8) (component‑wise independent Gaussian).
Updated message vector:
m’ = p_eff * m + (1 - p_eff) * n
Finally, renormalize:
m’‘ = m’ / ||m’||
3.2 Message Integrity
After a message has traversed a path, its integrity is defined as the cosine similarity to the original message:
Integrity = ( m . m0 ) / ( ||m|| * ||m0|| ) = m . m0
since both vectors are normalized.
4. Kompromat Accumulation
Each edge (u,v) in E accumulates a kompromat value. When a message travels from u to v through agent v, a delta delta is added to the edge’s kompromat and to the kompromat exposure of node v.
4.1 Base Delta
delta0 = 0.5 * ln(2)
delta = delta0 * (1 + w_spi * SPI_v)
* (1 - alpha_c * C_v)
* (1 - alpha_iq * IQ_v)
* (1 + alpha_n * N_v)
Where:
w_spi =
spi_weight(parameter)alpha_c =
conscientiousness_protection(parameter)alpha_iq =
iq_protection(parameter)alpha_n =
neuroticism_risk(parameter)
If the edge (u,v) is a bridge edge (i.e., belongs to B), the delta is multiplied by an additional factor:
delta_final = delta * B_bonus
where B_bonus = bridge_bonus (parameter).
4.2 Update
kompromat(u,v) += delta_final
kompromat_exposure_v += delta_final
5. Flip Mechanism
Agents who are bridge nodes are subject to capture and potential flipping. A bridge node may become captured (probability per time step = p_capture = capture_rate) and, if captured, may flip with probability p_flip. Flipped agents then attempt to capture and flip their neighbors.
5.1 Flip Probability for an Individual
Let the agent have traits Aw, N, C, IQ. Parameters:
awareness_flip_peak= A_peakneuroticism_risk= alpha_n (same as in kompromat delta)conscientiousness_protection= alpha_ciq_protection= alpha_iq
Awareness effect – an inverted‑U shape with maximum at A_peak:
norm = if 0 < A_peak < 1: 1 / (2 * A_peak * (1 - A_peak)) else 1
aware_effect = 2 * Aw * (1 - Aw) * norm
Other trait effects:
neurotic_effect = N * 0.3
consc_effect = (1 - C) * 0.2
iq_effect = (1 - 0.5 * IQ) * 0.1
Base probability (before capture intensity scaling):
p_base = 0.1 + aware_effect + neurotic_effect + consc_effect - iq_effect
Clipping:
p_base = max(0.01, min(0.95, p_base))
When a capture event occurs, the final flip probability is:
p_flip = 1 - (1 - p_base) ^ I
where I is the capture intensity. In the simulation, I = 1.0 when called from the main loop, and also for cascade flips.
5.2 Cascade
When a bridge node i flips, it attempts to capture each neighbor j with probability:
p_capture_cascade = Aw_i * Aw_j * 0.5
If j becomes captured, it then rolls for flip with probability p_flip(j) (using the same flip probability function with I = 1.0). Flipped nodes do not trigger further cascades (only the originally flipped node does).
6. Simulation Procedure
Each simulation runs for T = 3000 steps. At each step:
Message source and target selection
With probability 0.9: choose two different communities uniformly at random; pick one random node from the first community as source, one random node from the second community as target.
Otherwise: pick two distinct nodes uniformly at random from all N agents.
Path finding
Compute shortest path (unweighted) from source to target. If no path exists (disconnected graph – extremely rare), skip step.Message traversal
Initialize a new message m0 (random normalized vector).
For each hop along the path (excluding the source):Degrade the message through the current node (see §3.1).
Update kompromat on the traversed edge and on the node (see §4).
If the node is a bridge node, record its SPI value and the per‑hop degradation = (1 - integrity) / path_length for later analysis.
Capture events
For every bridge node that is not already captured or flipped:With probability p_capture =
capture_rate, the node becomes captured.Immediately after capture, the node attempts to flip with probability p_flip(I = 1.0).
If flip occurs, execute cascade (§5.2).
7. Metrics Computed per Simulation
After 3000 steps, the following aggregate metrics are calculated from the final state.
Let A be the set of all agents, E the set of all edges, B the set of bridge edges, N_B the set of bridge nodes.
7.1 Edge‑Based Metrics
bridge_edge_pct = (|B| / |E|) * 100
kompromat_concentration = sum_{e in B} kompromat(e) / sum_{e in E} kompromat(e)
7.2 Agent‑Based Correlations (on Bridge Nodes)
Only computed if |N_B| >= 10.
For each trait X in {SPI, IQ, C, N}:
r_X = Pearson_correlation( X_i , kompromat_exposure_i ) for all i in N_B
7.3 Flip Rates
bridge_flip_rate = count{ i in N_B : flipped_i = True } / |N_B|
7.4 Archetype Stratification
Let N_lawyer be the count of lawyer agents in the whole population, N_lawyer_bridge the count of lawyers among bridge nodes. Similarly for impulsive.
lawyer_representation_ratio = ( N_lawyer_bridge / |N_B| ) / ( N_lawyer / N )
impulsive_representation_ratio = ( N_impulsive_bridge / |N_B| ) / ( N_impulsive / N )
7.5 SPI Advantage
lawyer_spi_advantage = mean( SPI for lawyer_bridge ) - mean( SPI for other_bridge )
7.6 Flip Ratio for Impulsive
impulsive_flip_ratio = mean( flipped for impulsive_bridge ) / mean( flipped for other_bridge )
If denominator is zero, the ratio is set to 1.0.
7.7 Integrity Mitigation
Let P be the set of all message paths. For each path, record:
mean_SPI_bridge = mean( SPI of bridge nodes along the path )
degradation_per_hop = (1 - integrity) / path_length
Only the last 500 messages (or all if fewer) are used.
integrity_mitigation_r = Pearson_correlation( mean_SPI_bridge , degradation_per_hop )
8. Parameter Sweep Design
The model has 8 tunable parameters. Each is varied independently over 5 levels, with 5 replicates per parameter‑value combination. All other parameters are held at baseline values.
Baseline values (also the default when a parameter is not being swept):
bridge_bonus: 6.0
spi_weight: 3.0
conscientiousness_protection: 0.2
iq_protection: 0.2
neuroticism_risk: 0.8
capture_rate: 0.005
awareness_flip_peak: 0.5
bridge_selection_beta: 2.0
Parameter ranges (5 levels each):
bridge_bonus: {1, 3, 6, 10, 15}
spi_weight: {0, 1, 2, 3, 4}
conscientiousness_protection: {0, 0.2, 0.4, 0.6, 0.8}
iq_protection: {0, 0.2, 0.4, 0.6, 0.8}
neuroticism_risk: {0, 0.4, 0.8, 1.2, 1.6}
capture_rate: {0.001, 0.002, 0.005, 0.01, 0.02}
awareness_flip_peak: {0.3, 0.4, 0.5, 0.6, 0.7}
bridge_selection_beta: {0, 1, 2, 3, 4}
Total simulations: 8 * 5 * 5 = 200. Each simulation uses 500 agents and runs for 3000 steps. Seeds are deterministic: 2026 + sim_index * 17.
9. Data Analysis Methodology
After collecting results from all 200 simulations into a single dataframe D, the following analyses are performed.
9.1 Effect Magnitude Ranking
For a given metric M and a parameter P (with at least two distinct tested values), let:
mu_P(v) = mean of M over all simulations where P = v
Delta_abs = max_v mu_P(v) - min_v mu_P(v)
M_bar = overall mean of M across all simulations
Delta_norm = Delta_abs / abs(M_bar)
Parameters are ranked by Delta_norm (descending) for each metric; top 5 are reported.
9.2 Main Effect Plots
For each parameter P, the mean of three key metrics – kompromat_concentration, spi_komp_r, lawyer_representation_ratio – is plotted against the parameter levels.
9.3 Optimal Regime Identification
For each theoretical claim, a conditional filter is applied to the dataframe to select simulations that satisfy the claim. Then the median (or mode, if appropriate) of relevant parameter values among those simulations is reported as the recommended operating regime.
Examples:
SPI dominant:
spi_komp_r > 0.15and greater than all other trait–kompromat correlations.Protective IQ/Consc: both
iq_komp_r < -0.1andconsc_komp_r < -0.1.Neuroticism positive:
neuro_komp_r > 0.1.Lawyer overrepresentation:
lawyer_representation_ratio > 1.2.Impulsive underrepresentation:
impulsive_representation_ratio < 0.8.Impulsive high flip:
impulsive_flip_ratio > 1.2.Kompromat concentration 70‑75%:
0.7 <= kompromat_concentration <= 0.75.Good mitigation:
integrity_mitigation_r < -0.3.
9.4 Trade‑off Analysis
Pearson correlations are computed between pairs of outcome metrics that represent potentially conflicting objectives, e.g.:
lawyer_representation_ratiovskompromat_concentrationspi_komp_rvsconsc_komp_rbridge_selection_betavsbridge_flip_rate
9.5 Summary Statements
The final section aggregates the evidence for each original intuition, classifying it as STRONGLY SUPPORTED, SUPPORTED, ENGINEERED, or CONFIRMED based on the quantitative results from the sweep.
10. Reproducibility Notes
Random seeds: Each simulation receives a deterministic seed derived from a global counter; the notebook sets
np.random.seed(2026)at the start, but individualrun_single_simulationcalls override it with the per‑simulation seed.Stochastic processes: All draws (trait generation, edge selection, message noise, capture events) are handled by
numpy.randomand are reproducible given the seed.Deterministic components: Network community sizes, shortest‑path computation, and all aggregations are deterministic functions of the random draws.
Parameter sweep: One‑at‑a‑time variation from baseline ensures clean estimation of main effects, but interaction effects are not systematically explored.
This document provides a complete, standalone mathematical description of the model and analysis. All equations are presented in ASCII format and can be directly translated into any programming language or mathematical notation system. The methodology is fully repeatable given the same parameter sets and random seeds.
Until next time, TTFN.